

�Е�7̖ocr�����R�e-�Е�7̖ocr�����R�eϵ�y-�Е�7̖ocr�����R�e���d v7.0��ȫ��

- ܛ����С���鿴
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2023-12-28
- ܛ����ͣ����aܛ��
- ���]�Ǽ�:
- �\�Эh����XP,Win7,Win8,Win10,Win11
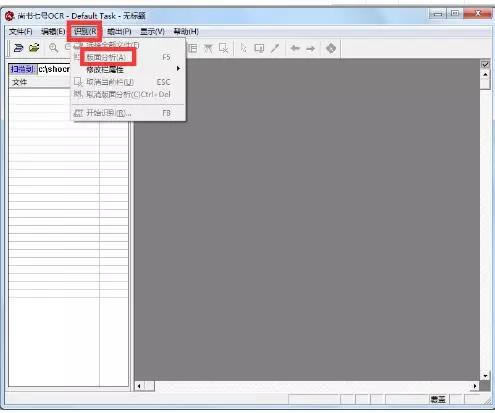
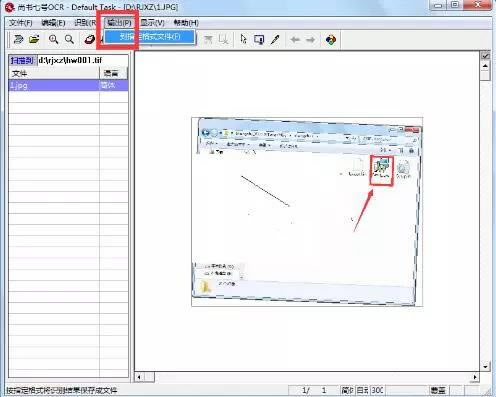
 �Е�7̖ocr�����R�eϵ�y�ǿ��������R�e���ߣ����DƬ�е������D���ɾ����ĵ����֣��M������ęn����������F��Ϣ�����F���������R�e���w�����Ρ��������w�֡�GBK�h���ܲ�ͬ����ģʽ����ܛ��ϵ�y�m���ڂ��ˡ�С�͈D���^��С�͙n���^��С����I�M�д�Ҏģ�ęnݔ�룬�D����ӡ�������Y����ӻ���ܛ��ϵ�y�� �Е�7̖ocr�����R�eϵ�y�ǹ���1���R�e�ַ� �Е�7̖ocr�����R�eϵ�y���cֱ���\�г���setup.exe���������b����ʾ���Ϳ�����ɰ��b������ �R�e�ַ����w�ַ���������GB2312-80��ȫ��һ�������h��6800������ ��Ӣ���ַ����� �����ּ������˺��w�h���⣬߀���Ի��R�_�����w��5400�����Լ���۷��w�ֺ�GBK�h�֡� �R�e���w�N����R�e���w�����Ρ������ڡ�κ�����`�����A�w���п���һ�ٶ�N���w����֧�ֶ�N���w���š� �R�e��̖��̖ С��̖���w�� �����R�e�����Ԅ��Дࡢ��֡��R�e��߀ԭ���Nͨ����ӡˢ�w���� ��֧�ַ��wWINDOWSϵ�y �Е�7̖ocr�����R�eϵ�yʹ�÷����Ò���x��������ֈD���܌����e�����M�о��ģ��ڽ̌W�У���Ҫ���������R�eܛ���������ֈD���M���R�e�����D���ʽ�D�����ı���ʽ����Ҋ�������R�eܛ���кܶ࣬��Ҫ���ܻ�����ͬ���Е���̖�������к܃����һ����Е���̖�����ֈD���R�e�D�����^�̣����������ˆΣ�“�ļ�”��“��”��“�R�e”��“ݔ��”���Ժܷ������ɡ����w���E�飺 ���E2��������ĈD����M���{�� �x��“��”�ˆ���“�D������̎��”�Ӳˆ��µ�“�D��퓵ăAбУ��”(�ṩ�ԄӺ��քӌ��F����)��“���D”�����������ĈD����M���{����
 �Е���̖���ԄӰ���������ܺ��������s־�ȏ��s�İ��棬Ҳ�ܱ��ֺܸߵķ������_�ʡ� �O�úú�ֱ���c��“�_ʼ�R�e”�İ��o�Ϳ����M�������R�e�ˡ�
 ϵ�yܛ��һ������Ӌ��Cϵ�yُ�I�r�S�C�y���ģ�Ҳ���Ը�����Ҫ���а��b�� |
1��ȼ��gwin10��ʽ��ghost��32λ����Ş......
2���ѻ��@win10 X86 ghost �˜�ͨ......
3���ѻ��@Win10_Ghost Win10 64......
4����ľ�L GHOST WIN10 X64 �����b......
5��ȼ��gGHOST WIN10 X64 ���F���I......
6�Pӛ��Win10ϵ�y 64λ�ٷ���ʽ��2023��......
7�Pӛ��win10��ʽ��ghost��32λ����Ş��......
8����ľ�Lwin10��32λ��ghost �������I......