

���h��ocr���M���İ桿�h��ocrܛ�����d v6.0 �e��

- ܛ����С���鿴
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2025-01-09
- ܛ����ͣ����aܛ��
- ���]�Ǽ�:
- �\�Эh����XP,Win7,Win8,Win10,Win11
ܛ����B�h��ocr���M���İ���һ��ʮ�ֺ��õ������R�e���ߡ��h��ocr�R�eܛ����Ҫ���Ժ��s���µĽ���ʬF���Ñ�����ǰ��ͬ�r����������Ĺ��ܲ��֣�ʹ���@��ܛ��׃������M�£������Ñ���ϲ�ۡ��h��ocr�e����Ñ��ṩ�DƬ�ļ��R�e���գ��܉���Ч̎��PDF�ļ����������R�e�ʴ_��ʮ�ָߣ��ٶ��ַdz��졣������Ą��ˣ��s�o���d�ɡ�
�h��ocr���M���İ�ܛ����ɫ1.�h��OCR�R�eܛ���ٷ������_�ʸߣ��R�e�ٶȿ졢����̎�����ܡ� 2.֧��̎���Ҷȡ���ɫ���ڰ����Nɫ�ʵ�BMP��TIF��JPG��PDF��N��ʽ�ĈD���ļ��� 3.���R�e���w�����w��Ӣ�����N�Z�ԡ� 4.�h��PDF OCR���к������õı����R�e���ܡ� 5.����TXT��RTF��HTM��XLS��Nݔ����ʽ��������Ҋ�����õİ���߀ԭ���ܡ� 6.֧��������PDF��ֱ���D�Q�͈D����PDF��OCR�R�e�� 7.ֱ���D�Q������PDF�ļ���RTF�ļ����ı��ļ���
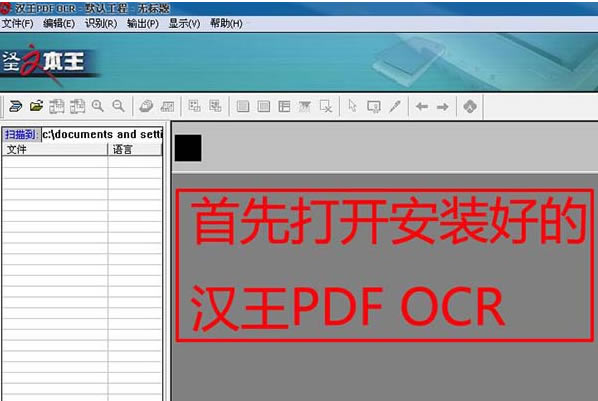
�h��ocr���M���İ氲�b�̳�-�ı�վ���dܛ��֮�≺���\��exe���ó��� -�c����һ�����x���˺ð��b·���� -���b��ɣ�����ʹ�á� �h��ocr���M���İ�ʹ�÷���1�����ȴ��_���b�õĝh��ocr��
2���c���ļ�——���_�D�� 3���ڏ����Ĵ��_�D���ļ��У�ֱ���x��PDF�ļ����˕r�·���“pdf�D�Q��TXT�ļ�”���ɻ�׃�ڞ�ɲ������c��ԓ̎������ֱ�ӌ���txt�ļ������Ǵ˷N����ᘌ�PDF�ļ��|���ܸߵ���r���ļ��|������ֱ�Ӳ��ô˷N�������`���ʺܸߡ� 4����PDF�ļ��|�����ߵ���r�£�ֱ���x��pdf�ļ����c��“���_”�� 5�����ԓpdf�ļ��ж�퓣���������“�x���ֶ��PDF”���x����Ҫ�������ֵ�퓔�(�����ȫ�x)���c���_���� 6�����_�����ļ��ڳ��Fԓ�ļ����ڽ����·����@ʾPDF�ļ�ԓ퓾��w��r�� 7���x���ļ�����Ҫ�D�Q��ԓ�PDF�ļ���(��ȫ�x)���ڹ��ߙ��c��“�R�e”-“�_ʼ�R�e”(��ֱ�Ӱ�F8)�� 8���˕r���ڽ����Ϸ����@ʾ�����R�e���R�e��ɺ��ڽ����Ϸ����@ʾ�R�e�Y�����˕r��PDF�ļ��|�����ߵ���r����һЩ�e�`�����ք��������ɡ� 9���ڽ����Ϸ����@ʾ�R�e�Y��̎���x����Ҫ���Ƶ����֣��c��������I���x���Ƽ���ճ�Nʹ�á� |
1��ȼ��gwin10��ʽ��ghost��32λ����Ş......
2���ѻ��@win10 X86 ghost �˜�ͨ......
3���ѻ��@Win10_Ghost Win10 64......
4����ľ�L GHOST WIN10 X64 �����b......
5��ȼ��gGHOST WIN10 X64 ���F���I......
6�Pӛ��Win10ϵ�y 64λ�����e �ٷ���ʽ��......
7�Pӛ��win10��ʽ��ghost��32λ��������......
8����ľ�Lwin10��32λ��ghost �����e......