

tesseract ocr��X�˹ٷ�����2024���°�Gɫ���M���d���b
- ܛ����С���鿴
- ܛ���Z�ԣ����w����
- �ڙʽ�����Mܛ��
- ���r�g��2024-07-18
- ܛ����ͣ����aܛ��
- ���]�Ǽ�:
- �\�Эh����XP,Win7,Win8,Win10,Win11
ܛ����Btesseract ocr��ԭ�Ȼ����_�l�ĈD���R�e죬����ɞ�Open source�����f�����ĈD���R�e�������������������ṩ�İ汾��4.0.0 for windows��
ʹ�÷��� ���d����M�а��b,Ĭ�J��r�°��b������o������ϵ�y�h��׃��,��ָ���bĿ䛣�֮�����ͨ�^DOS����������Ŀ��\��tesseract�������b��ɺ�Ŀ�����:
tessdata Ŀ䛴�ŵ����Z���֎��ļ������������н����п����õ��ą������������ļ�. �@�����b����Ĭ�J������Ӣ���֎졣
������F����ݔ������ʾ���b������
�Y����:
���:
|
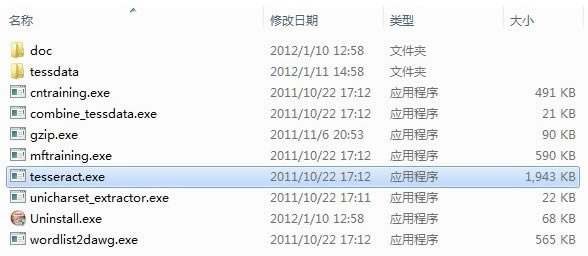
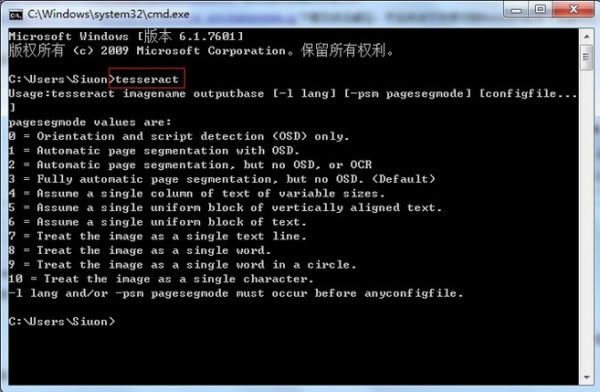
 ����D�P��Ŀ��£��ψD:
����D�P��Ŀ��£��ψD: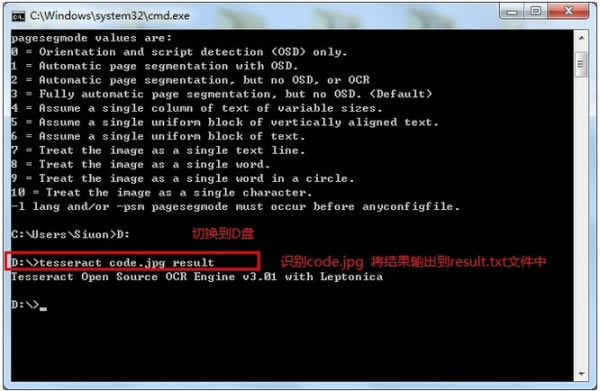
1��ȼ��gwin10��ʽ��ghost��32λ����Ş......
2���ѻ��@win10 X86 ghost �˜�ͨ......
3���ѻ��@Win10_Ghost Win10 64......
4����ľ�L GHOST WIN10 X64 �����b......
5��ȼ��gGHOST WIN10 X64 ���F���I......
6�Pӛ��Win10ϵ�y 64λ�ٷ���ʽ��2024��......
7�Pӛ��win10��ʽ��ghost��32λ����Ş��......
8����ľ�Lwin10��32λ��ghost �������I......